Excel Verilerinde Isolation Forest Algoritması ile Anomali Tespiti: Python ile Uygulamalı Bir Rehber
Anomalilerle neden ilgilenmeliyiz?
Veri analizi süreçlerinde çoğu zaman verilerin büyük kısmı belirli bir örüntüye ya da dağılıma uyar. Ancak her zaman bu örüntüyü bozan, “sıradan” olmayan, istatistiksel anlamda uç değer ya da “anormal” olarak tanımlanan veri noktaları karşımıza çıkar. İşte bu noktada anomali tespiti (anomaly detection) devreye girer.
Anomaliler, finansal dolandırıcılıktan medikal teşhislere, üretim hatalarından siber güvenliğe kadar birçok alanda kritik öneme sahiptir. Bu nedenle, verimizi temizlemeden ya da modellemeden önce anomalileri tanımlamak ve mümkünse elemek gerekir.
Bu yazıda, Python programlama dili ve Isolation Forest algoritması kullanılarak, Excel dosyasındaki bir veri kümesi üzerinde anomalilerin nasıl tespit edileceğini adım adım gösteriyorum. Ayrıca IQR (Interquartile Range) yöntemiyle de aykırı değer tespiti yapılmıştır. Yazının sonunda, anomaliler temizlendikten sonra veri dağılımının histogramlarla nasıl değiştiğini de görebileceksiniz.
Isolation Forest Nedir?
Isolation Forest, yani “izolasyon ormanı”, anomali tespiti için geliştirilmiş denetimsiz bir makine öğrenmesi algoritmasıdır. Temel prensibi oldukça sezgiseldir: anormal veriler, normal verilere kıyasla daha kolay ayrıştırılır (izole edilir). Bu sayede, verinin yapısı hakkında ön bilgiye ihtiyaç duymadan aykırı değerleri başarılı bir şekilde tanımlayabilir.
Avantajları arasında:
-
Yüksek boyutlu verilerle iyi çalışması,
-
Etkin hesaplama süresi (büyük veri setleri için uygundur),
-
Etiketli veriye ihtiyaç duymaması yer alır.
Uygulama: Excel Verisinde Anomali Tespiti Adımları
Bu bölümde, adım adım Python kodları ile nasıl Isolation Forest modeli kuracağımızı ve anomalileri tespit edeceğimizi göstereceğim.
1. Gerekli kütüphaneleri içe aktaralım
İlk olarak pandas, numpy ve görselleştirme kütüphanelerimizi içe aktarıyoruz. Ayrıca IsolationForest algoritması sklearn.ensemble modülünden çağrılmaktadır.
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
import seaborn as sns
2. Excel dosyasından veriyi okuyalım
Veri setimiz “Calculation.xlsx” adında bir Excel dosyasından okunuyor. İlk olarak tamamı, ardından yalnızca gerekli sütunlar usecols parametresi ile okunmuştur.
df = pd.read_excel("C:/Calculation.xlsx")
required_columns = [0, 1, 2, 3]
required_df = pd.read_excel("C:/Calculation.xlsx", usecols = required_columns)
3. Modeli tanımlayıp eğitelim
Isolation Forest modelini belirli hiperparametrelerle tanımlayıp sadece “Result” sütunu üzerinden eğitiyoruz.
model = IsolationForest(
n_estimators=100,
max_samples='auto',
contamination=float(0.1),
max_features=1.0,
bootstrap=True,
n_jobs=-1,
random_state=42,
verbose=0
)
model.fit(required_df[["Result"]])
Burada dikkat edilmesi gereken parametrelerden bazıları:
contamination: Beklenen anomali oranıdır (bu örnekte %10).
n_estimators: Kullanılacak ağaç sayısı.
max_samples: Her ağaç için örneklenen alt küme sayısı.
bootstrap: Rastgele örnekleme yapılmasını sağlar.
4. Anomali skorlarını ve tahminlerini ekleyelim
Modelin karar fonksiyonu ile her satıra ait skorları ve -1 (anomali) veya 1 (normal) etiketlerini ekliyoruz.
required_df['scores'] = model.decision_function(required_df[['Result']])
required_df['anomaly'] = model.predict(required_df[['Result']])
5. Tespit edilen anomalileri inceleyelim
Model tarafından anomali olarak etiketlenen satırlar listelenir:
anomaly = required_df.loc[required_df['anomaly'] == -1]
print(anomaly)
Çıktıdan bazı örnekler:
Sample Treatment Period Result scores anomaly
3 1 Tr-4 2 0.636951 -0.032099 -1
...
157 5 Tr-2 48 6.641357 -0.017261 -1
Ayrıca anomalilerin indekslerini ayrı bir listeye alabiliriz:
anomaly_index = list(anomaly.index)
print(anomaly_index)
Çıktı: [3, 10, 14, 15, 56, 72, 81, 84, 128, 132, 133, 145, 149, 152, 153, 157]
6. Anomalileri veri setinden silelim
Silme işleminden önce satır sayısını kontrol edelim:
required_df.shape
Çıktı: (160, 4)
Şimdi, drop() yöntemiyle anomali satırlarını çıkaralım:
required_df.drop(anomaly_index, axis=0, inplace=True)
required_df.shape
Yeni boyut: (144, 6)
7. Histogram ile veri dağılımını gözlemleyelim
Anomaliler temizlendikten sonra dağılımın nasıl değiştiğini görselleştirebiliriz:
plt.figure(figsize=(10, 5))
plt.hist(df.Result)
plt.hist(required_df.Result)
plt.show()
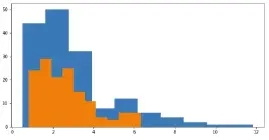
Bu grafik, anomali verilerden arındırılmış veri kümesinin daha düzgün bir dağılıma sahip olduğunu açıkça gösterecektir.
Sonuç ve Öneriler
Bu çalışmada, Python ile Excel verilerinde anomali tespiti nasıl yapılır sorusuna cevap verdik. Isolation Forest algoritması, özellikle denetimsiz veri setlerinde aykırı değerleri izole ederek tespit etmek için güçlü bir araçtır. Aykırı verilerin temizlenmesiyle birlikte daha tutarlı analizler, daha güvenilir modeller ve daha doğru sonuçlar elde edilebilir.
🔍 Ayrıca IQR (Interquartile Range) gibi istatistiksel yöntemleri de paralel olarak kullanmak, modelinizin sağlamlığını artırabilir.
Veri analizine meraklı olan herkes için bu tür araçlar, analiz kalitesini birkaç seviyeye çıkaracaktır. Umarım bu içerik sizin için hem öğretici hem de uygulanabilir olmuştur.